Dataset generation for code LLMs
In this blog post, we're looking at dataset preparation for code LLMs. I will mainly be looking at three papers:
- DeepSeek-Coder-V2
- Qwen2.5-Coder Technical Report
- OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
| Model | Base Model training tokens | Additional training tokens | % Code | % Math | % Natural Language |
|---|---|---|---|---|---|
| Qwen2.5 | ? | 5.2T | 70% | 10% | 20% |
| DS-Coder-V2 | 4.2T | 6T | 60% | 10% | 30% |
| OpenCoder | X | 2T | 99.7% | 0.3%* | 0% |
* proportion of AutoMathText - more math might have been included via CommonCrawl as math-like URLs were included.
Dataset mix
Both DeepSeek-Coder-v2 and Qwen2.5-Coder use a combination of code,
math and natural language in the pre-training process. Qwen2.5-Coder ablates over
this ratio, and showed that 70:20:10 allows you to do well on code benchmarks, while
still performing well on non-code related datasets: 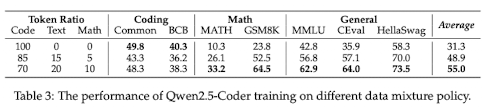 The authors claim, though, that the 7:2:1 ratio outperformed the others, even surpassing
the performance of groups with a higher proportion of code: "Interestingly, we found
that the 7:2:1 ratio outperformed the others, even surpassing the performance of
groups with a higher proportion of code." However, the table shows that code performance
is still the best when trained on 100% code. I'm not sure why that would be interesting
The authors claim, though, that the 7:2:1 ratio outperformed the others, even surpassing
the performance of groups with a higher proportion of code: "Interestingly, we found
that the 7:2:1 ratio outperformed the others, even surpassing the performance of
groups with a higher proportion of code." However, the table shows that code performance
is still the best when trained on 100% code. I'm not sure why that would be interesting
- including more domain-specific (natural language and math) data naturally makes the model better on these domains.
Now, how do we construct a huge code dataset? Let's look at the different approaches.
DeepSeek-Coder-V2 dataset
DeepSeek-Coder-V2 starts by collecting public repositories from GitHub (before November 2023). It then uses an initial filtering technique to filter out near-duplicates and low-quality code. This is what is removed:
- Files with average line lengths over 100 characters
- Files with a line length exceeding 1000 characters
- Files with fewer than 25% alphabetic characters
- Files where the string
<?xml version="appears in the first 100 characters (except for XSLT files) - HTML files with less than 20% code or fewer than 100 characters
- JSON and YAML files with a character count lower than 50 or more than 5000 This process is adapted from StarCoder. The result is 821B code tokens from 388 programming languages, and 185B code-related text tokens, such as markdown and issues.
Then, more code and math-related web texts are collected from CommonCrawl. Initially, data is selected from websites like StackOverflow, PyTorch and StackExchange. This initial data is used to train a fastText model to recall more coding and math web pages. For each domain in CommonCrawl, a percentage of web pages collected in the first iteration is calculated -- domains with more than 10% of web pages collected are classified as code-related or math-related. All of the URLs of these domains are then classified as math or code-related. This process is repeated three times.
FastText
fastText is an extremely fast text classifier created in 2016 by FAIR. The paper claims it can train a model on more than one billion word in less than ten minutes using a standard multicore CPU, and classify half a million sentences among ~312K classes in less than a minute. FastText averages word and n-gram embeddings into a hidden representation, feeding this into a linear classifier with hierarchical softmax - a bag of tricks for efficient text classification.
DeepSeek uses the Byte Pair Encoding tokenizer from DeepSeek-V2 to process the fastText input, which improves the recall accuracy for fastText.
The result is an additional 70B code-related tokens and 221B math-related tokens. The same pipeline is then applied to GitHub data (two iterations), resulting in an additional 94B code tokens.
Qwen2.5-Coder dataset
Qwen2.5-Coder also creates a dataset based on GitHub and CommonCrawl. Similarly, they initially apply the StarCoder filtering mechanism. However, they use the filtering technique from StarCoder-2 instead of the original StarCoder paper.
Text-Code data is retrieved from CommonCrawl using a 'coarse-to-fine hierarchical filtering approach'. A precise description of this method is not included in the paper - the authors mention that they use a set of filters using small models such as fastText, and do four iterations of this process. Each iteration adds fewer and fewer tokens to the dataset, because there are fewer and fewer relevant tokens to discover. However, adding these tokens still improves the performance of HumanEval and MBPP (performance in the plot is the average of these two datasets):
 As such, the initial dataset creation process sounds similar to the process described in DeepSeek-V2. After this process, Qwen2.5-Coder also adds Synthetic data generated by CodeQwen1.5, validated by an executor for validation, math data from Qwen2.5-Math, and text data from Qwen2.5.
More details on the dataset creation process are, unfortunately, not given.
As such, the initial dataset creation process sounds similar to the process described in DeepSeek-V2. After this process, Qwen2.5-Coder also adds Synthetic data generated by CodeQwen1.5, validated by an executor for validation, math data from Qwen2.5-Math, and text data from Qwen2.5.
More details on the dataset creation process are, unfortunately, not given.
OpenCoder dataset
Core dataset
Conversely, OpenCoder describes the dataset creation process in much more detail. Similar to DeepSeek and Qwen2.5-Coder, the dataset (named RefineCode) combines raw code and code-related web data.
The raw code comes from GitHub and The Stack v2, a dataset extracted from Software Heritage's (SWH) source code archive.
They exclude files larger than 8 MB and restrict the file types based on a list of programming languages from GitHub's linguist library, leading to 607 types of programming language files.
Part of the dataset creation pipeline can be found here.
Filtering
Exact deduplication removes 75% of files from the core dataset (!), done by computing the SHA256 hash value for each document. Files related to repositories with the highest star count are retained. Fuzzy deduplication further removes 6% of the core dataset. It is done by splitting the raw text into 5-gram pieces and then calculating a 2048 MinHash function. Then, copyright notices are removed from the beginning of files, and then Personally Identifiable Information is removed with a set of regular expressions. Then, three additional sets of rules are implemented to filter out low-quality code:
- Filtering based on common properties of text files, such as file size and number of lines.
- Filtering based on code-specific rules, e.g. number of variables, average function length, etc.
- Filtering based on language-specific rules for common programming languages. Then, Java and HTML files are downsampled as Java is very common, and HTML data is likely less informative.
To gather more data, OpenCoder uses a similar CommonCrawl filtering process as DeepSeek and Qwen2.5-Coder: they use a number of iterations of filtering and adding data based on fasttext classifiers. However, as their seed dataset, they use high-quality code-like data from CommonCrawl, selected via Autonomous Data Selection ADS.
Autonomous Data Selection
The paper Autonomous Data Selection with Zero-shot Generative Classifiers for Mathematical Texts describes a method to use language model's logits to figure out if input text is relevant. By integrating this method into a continual pre-training pipeline, the authors show that they can boost the performance on several math benchmarks. More precisely, AutoDS takes a strong base model (e.g. Qwen-72B) and prompt it with two yes/no questions assessing 1) the level of 'mathematical intelligence' in the text, and 2) its utility for future math learning. From the resulting logits on "YES" and "NO", a single real-valued is computed:
The model is prompted in such a way that it will only reply with or :
<system> You are ChatGPT, equipped with extensive expertise in mathematics and coding, and skilled in complex reasoning and problem-solving. In the following task, I will present a text excerpt from a website. Your role is to evaluate whether this text exhibits mathematical intelligence and if it is suitable for educational purposes in mathematics. Please respond with only YES or NO </system> User: {"url": "{url}", "text": "{text}" Does the text exhibit elements of mathematical intelligence? Respond with YES or NO Is the text suitable for educational purposes for YOURSELF in the field of mathematics? Respond with YES or NO
After applying the same fastText filtering process on FineWeb, Skypile, and AutoMathText, 330 GB of code-related web data were added to the dataset. The entire RefineCode dataset from OpenCoder consists of 960 billion tokens.
A few more interesting insights related to code dataset creation are highlighted. First of all, deduplication can be done at a repository level and a file level. The authors find that:
- Deduplication at the repository level results in almost 3 times as many remaining tokens as file-level deduplication.
- The downstream performance after file-level deduplication is better than the performance at the repository level
- For repository-level deduplication, 52 billion tokens exhibit complete character-level equivalence with another file
- Approximately 68 billion tokens can further be deduplicated after repository-level deduplication. The point is clear: file-level deduplication is better than repository-level deduplication.
Another small analysis is done on the importance of GitHub stars in the dataset. They train two LLMs, one trained on original data and one on repositories with at least five stars. The latter results in worse performance compared to the original dataset.
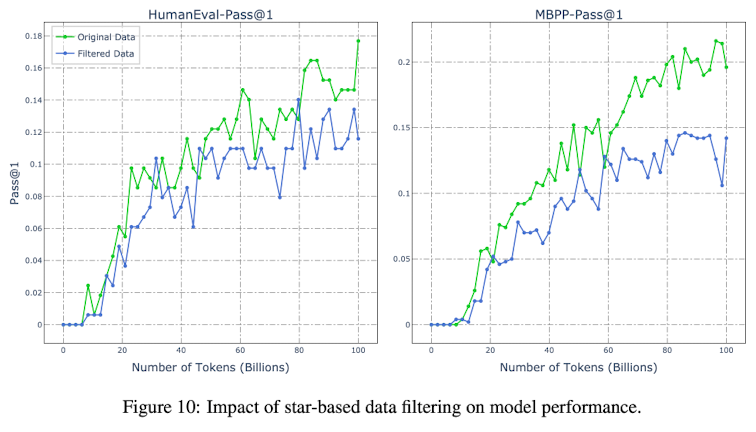 The intuition here is that although the code quality data might be better, the overall diversity of the dataset decreases too much with this filtering procedure, as shown by a simple 2D visualisation of the embeddings of both datasets:
The intuition here is that although the code quality data might be better, the overall diversity of the dataset decreases too much with this filtering procedure, as shown by a simple 2D visualisation of the embeddings of both datasets:
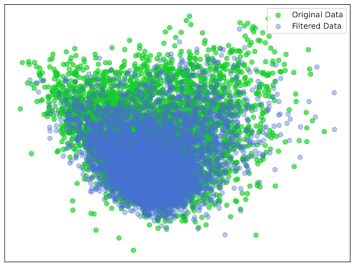
Conclusion
In this blog post, we've explored the dataset preparation strategies used by DeepSeek-Coder-V2, Qwen2.5-Coder, and OpenCoder. While each approach shares a common foundation—sourcing code from GitHub, CommonCrawl, and other web sources—they have slight differences in their filtering and deduplication techniques. However, iteratively discovering relevant data based on fastText is popular — DeepSeek clearly set a new standard for dataset creation here. In the next part of this series, we will dive into pre-training techniques and reinforcement learning approaches that incorporate compiler feedback to improve code generation.