Research notes: few-shot performance of vision-language models
This post contains my research notes on vision-language model (VLM) few-shot learning, which is the ability of these models to learn and perform tasks with a number of examples or "shots" as part of the prompt.
Introduction: GPT-3 and Flamingo
GPT-3 introduced the world to the few-shot abilities of LLMs - the paper is called "Language Models are Few-Shot Learners" for a reason. It demonstrated that larger models perform better with more shots compared to smaller models: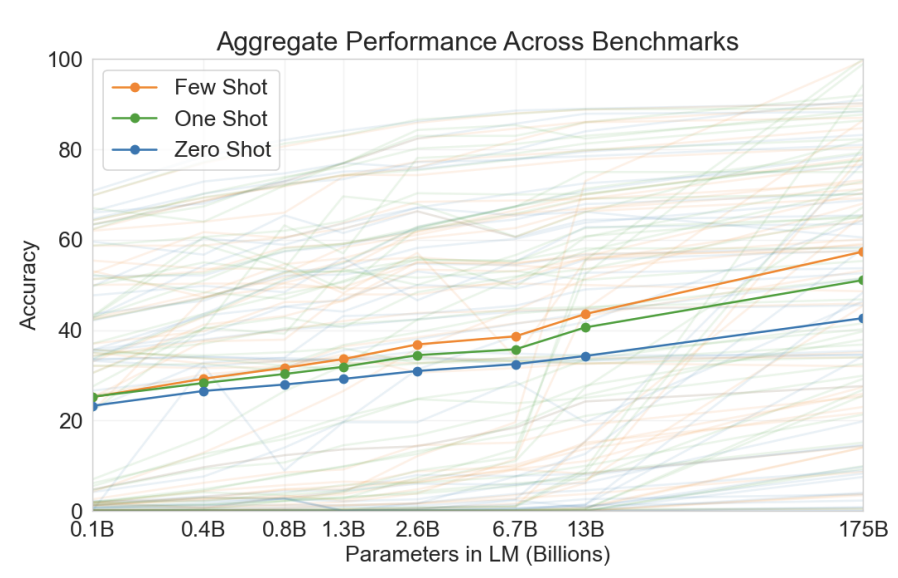
Few-shot learning applied to Vision-Language models (VLMs) was popularized in Flamingo: a Visual Language Model for Few-Shot Learning. It showed that few-shot learning could even outperform fine-tuned SoTA models at the time (2022):
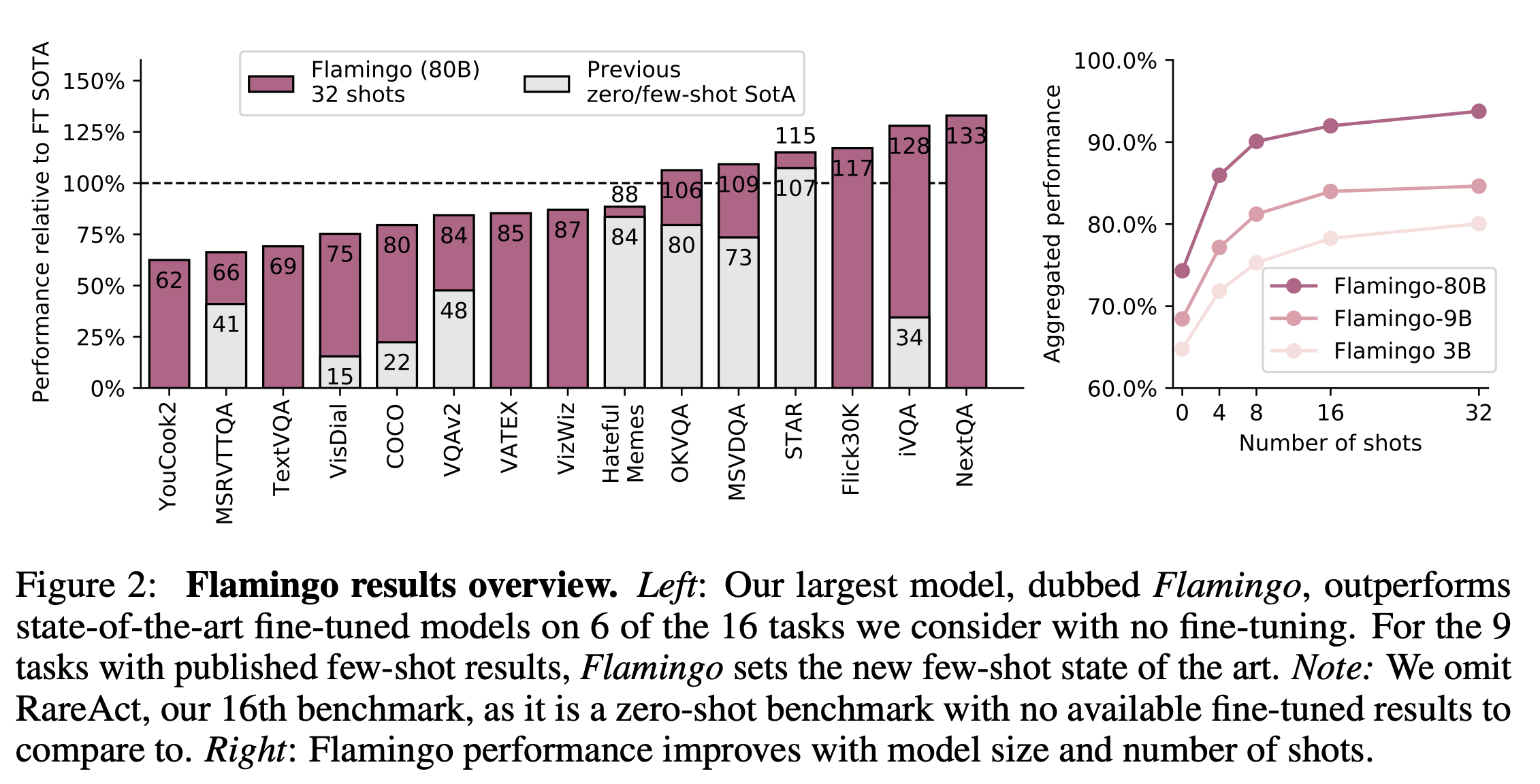
Flamingo's results are no longer SoTA and by quite some margin. Does few-shot learning work for the current SoTA VLMs?
SoTA VLMs & few-shot Learning
Qwen2-VL
Qwen2-VL is the current state-of-the-art language model, at least as reported on the VLM Leaderboard. Qwen-VL (the v1) still had one plot related to few-shot performance: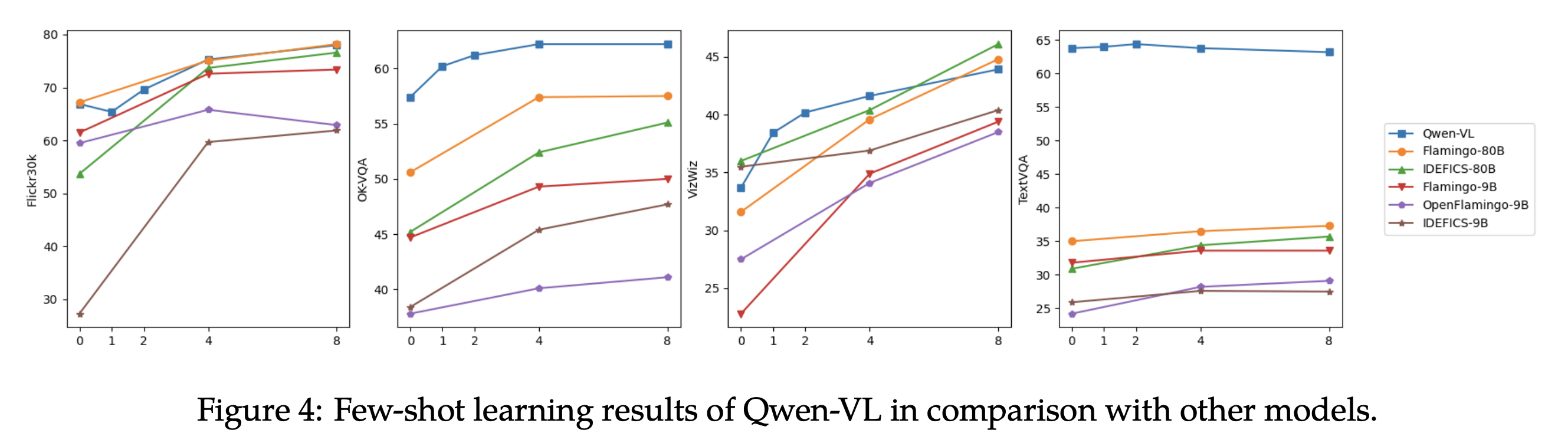
Here, we see that going from 0 to 4 shots improves performance on 3/4 datasets. However, we also see that few-shot learning doesn't work well on TextVQA, and on OK-VQA, performance only improves from 4 to 8 shots. Unfortunately, a similar analysis is missing for Qwen2-VL.
Llama-3.2 Vision & Gemini 1.5 Pro
LLama-3.2 Vision only works well with a single image, as the team reported. This is evidenced in this paper, where they compare the few-shot performance of different models, in this plot on classification datasets: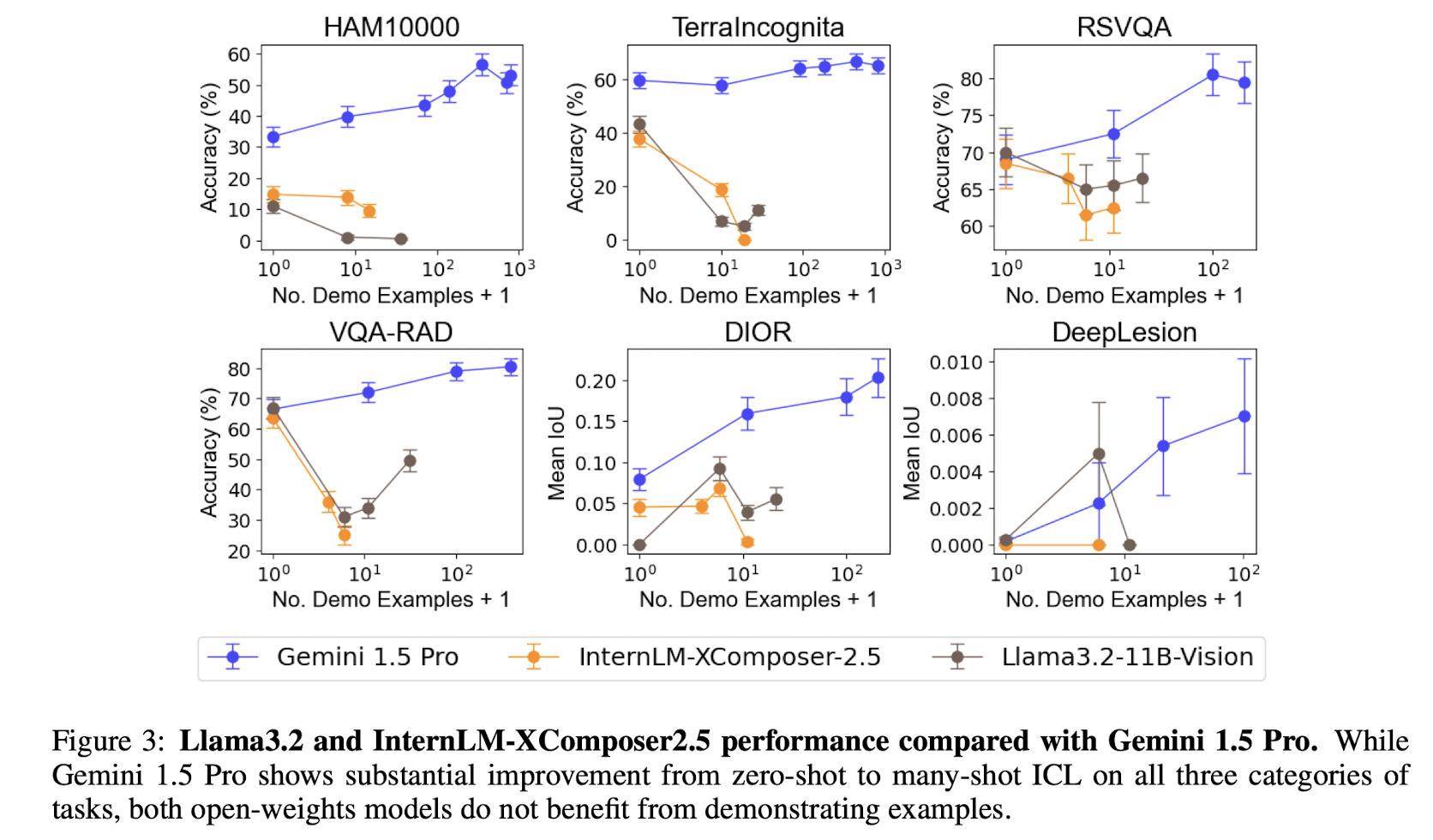
We see that the performance of LLama-3.2 generally decreases with more examples added to the prompt. Gemini 1.5 Pro does improve significantly with more shots, which hints at the use of a different training strategy - maybe Gemini was fine-tuned for longer on a multiple-image or few-shot setting? Comparing GPT-4o to Gemini, we see that Gemini is the more consistent few-shot learner:
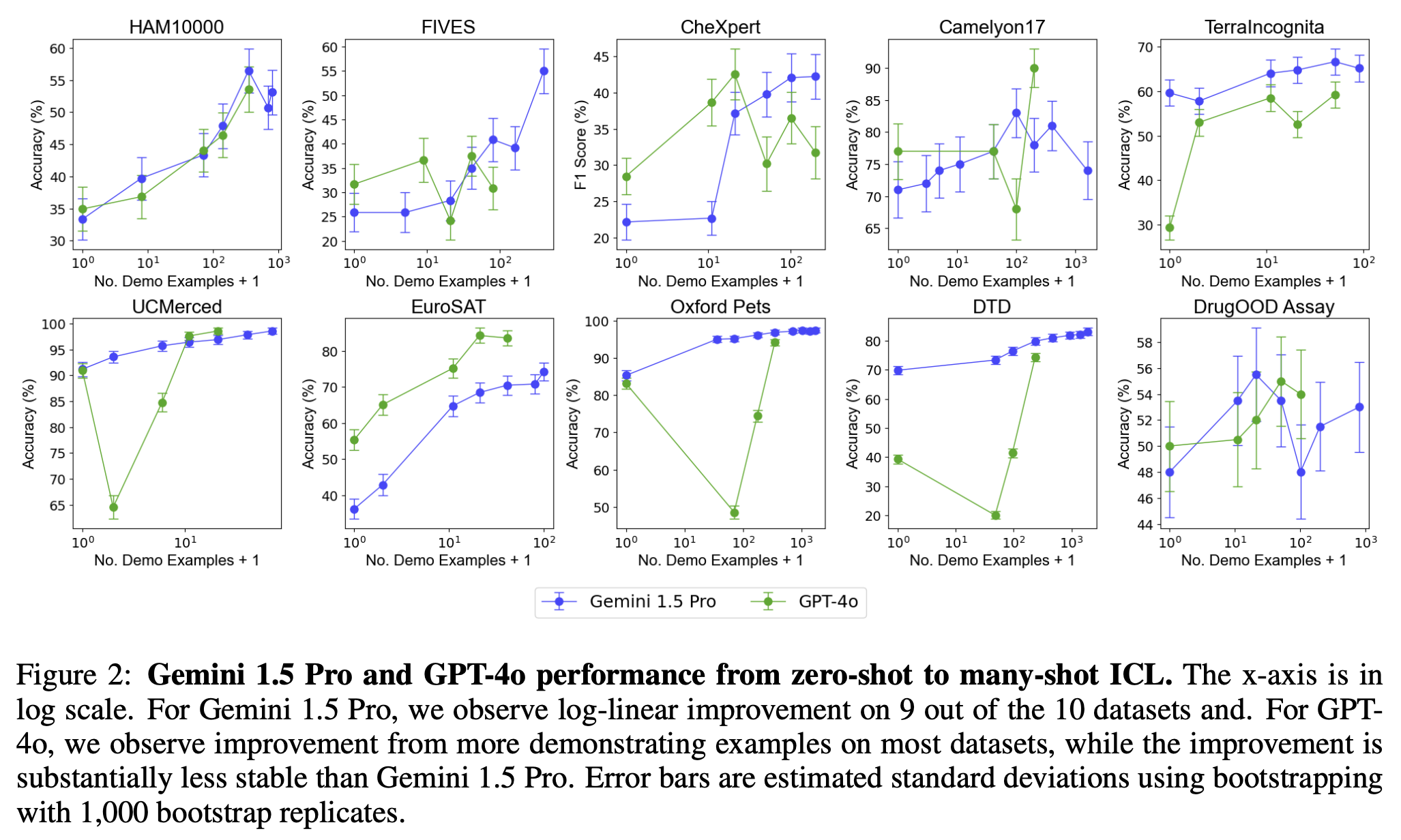
Note that the datasets reported in the two plots above are not the typical VLM datasets - they're mostly classification datasets. I couldn't find any good paper reporting how current SoTA models perform within a few-shot setting on standard VLM datasets.
Recently, we've seen at least two new recent models that report 'better-than-Qwen2-VL' 0-shot performance on at least a couple of vision-language tasks: o1 and Gemini 2.0:
| Gemini-2 | o1 | Qwen2-VL | GPT-4o | |
|---|---|---|---|---|
| MMMU | 70.7 | 77.3 | 64.5 | 69.1 |
| Mathvista | ? | 71.0 | 70.5 | 63.8 |
Benchmarking these models on their few-shot performance should be a good future (but expensive) eval opportunity.
What to Learn from Earlier Open-Source Models
Now that we have yet to see conclusive few-shot performance results on state-of-the-art VLMs, what can we learn by looking at smaller models? The paper "What Makes Multimodal In-Context Learning Work?" explores the effectiveness and limitations of few-shot learning for vision-language models (VLMs), specifically analyzing IDEFICS 9B. Their findings are as follows:1. Text drives few-shot learning
For visual question answering (VQA) tasks, removing images from the context leads to only a 1.2–1.5 point drop in performance. VQA tasks do not seem to use the in-context learning images much, at least when evaluated with IDEFICs. The idea here is that the text in in-context examples is useful when it carries significant semantic content. For VQA and captioning tasks, the text is semantically rich, and reduces the impact of the image in the context. For classification however, the textual content is limited as the text just contains a simple label. As a result, the role of images in the context is much larger in a classification setup. For example, on CIFAR-100 classification, removing or randomizing images reduces performance to or below zero-shot levels.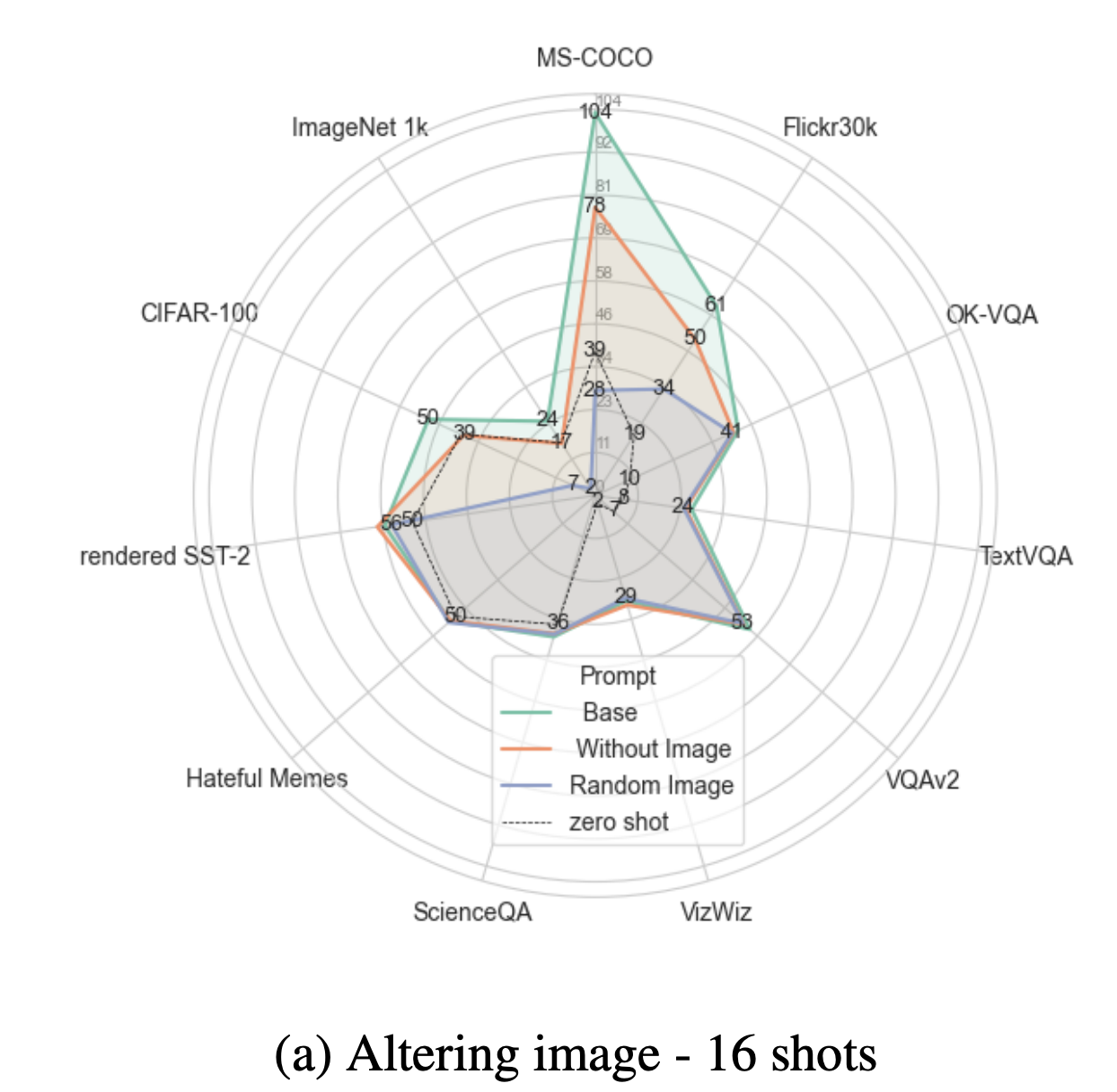
2. RICES improves few-shot performance but relies on shortcuts
The retrieval-based method RICES, used in Flamingo, selects demonstrations similar to the query using CLIP-based similarity scores. However, the improvements that result from this selection method seem to be primarily due to "shortcuts" where the retrieved responses already closely match the correct target.For classification tasks, few-shot learning with RICES performs no better than a k-nearest neighbors (KNN) baseline that performs majority voting over the labels in the context. For open-ended generation tasks (e.g., captioning and VQA), RICES provides measurable but limited gains. These findings suggest that RICES succeeds by retrieving outputs close to the correct answer rather than enabling genuine few-shot learning.
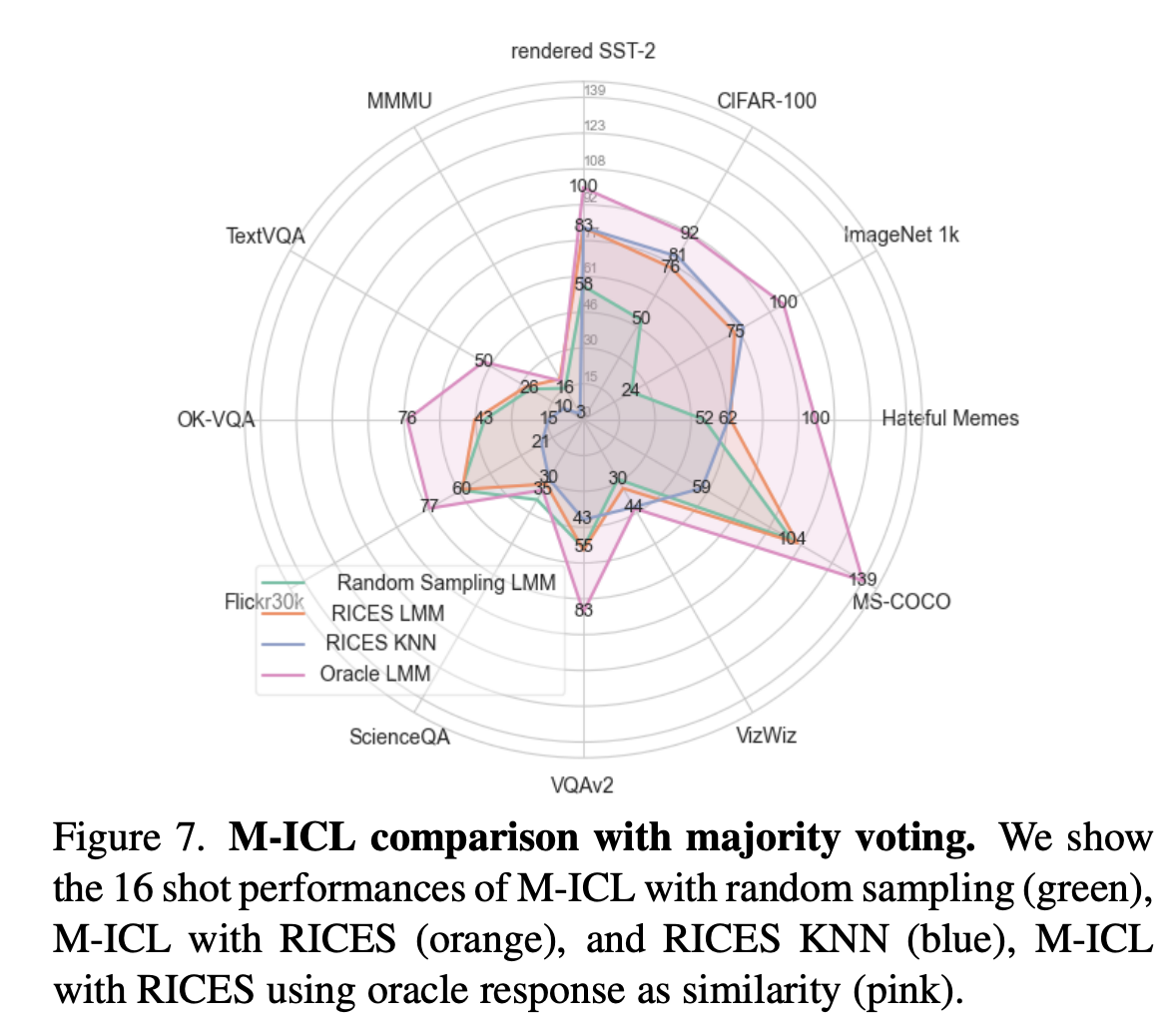
3. Recency Bias Leads to Copying the Last Demonstration
Few-shot learning has a recency bias, where the model tends to copy outputs from the last demonstration in the context:- In VQA tasks, the model replicates the last demonstration's response 12% of the time, regardless of the number of shots.
- For captioning, the copying frequency ranges from 24% with four shots to 4% with 32 shots, showing that increasing the number of examples reduces the copying effect.
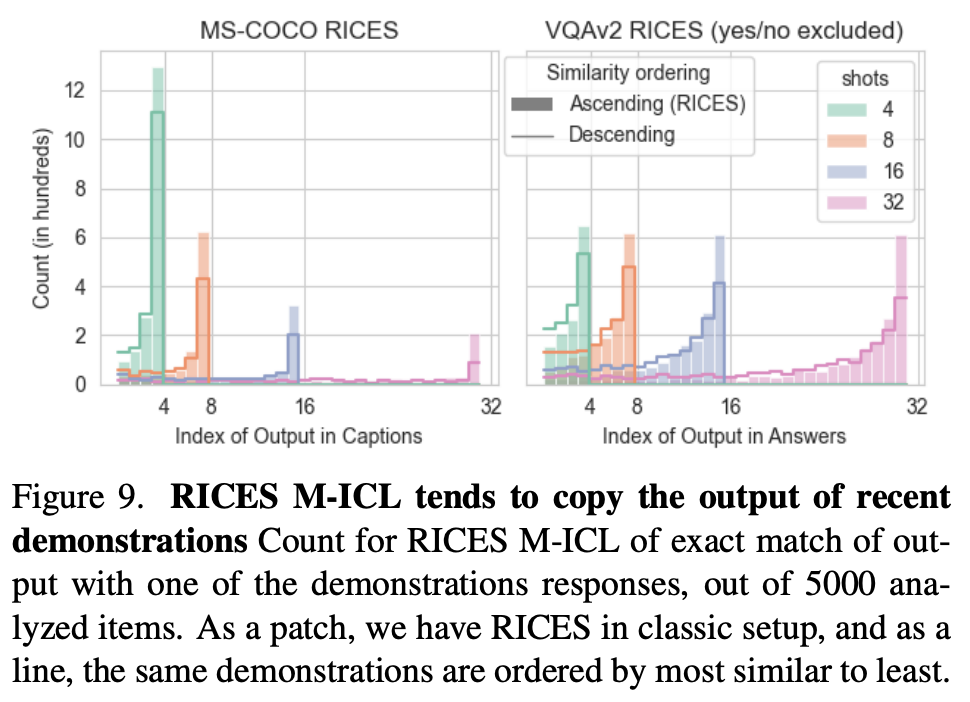
Adapting VLMs for Few-Shot Performance
If most open-source models do not perform well out-of-the-box in a few-shot learning setting, can we adjust them so that they do work well with more shots?Fine-tuning for few-shot performance
OpenFlamingo struggles to reproduce Flamingo's few-shot learning performance. Although performance generally improves with the number of in-context examples, the rate of improvement is lower than for the Flamingo models. The authors speculate that this has to do with the quality of the pre-training data, which mainly consists of sequences with few images (median of < 3 per sequence).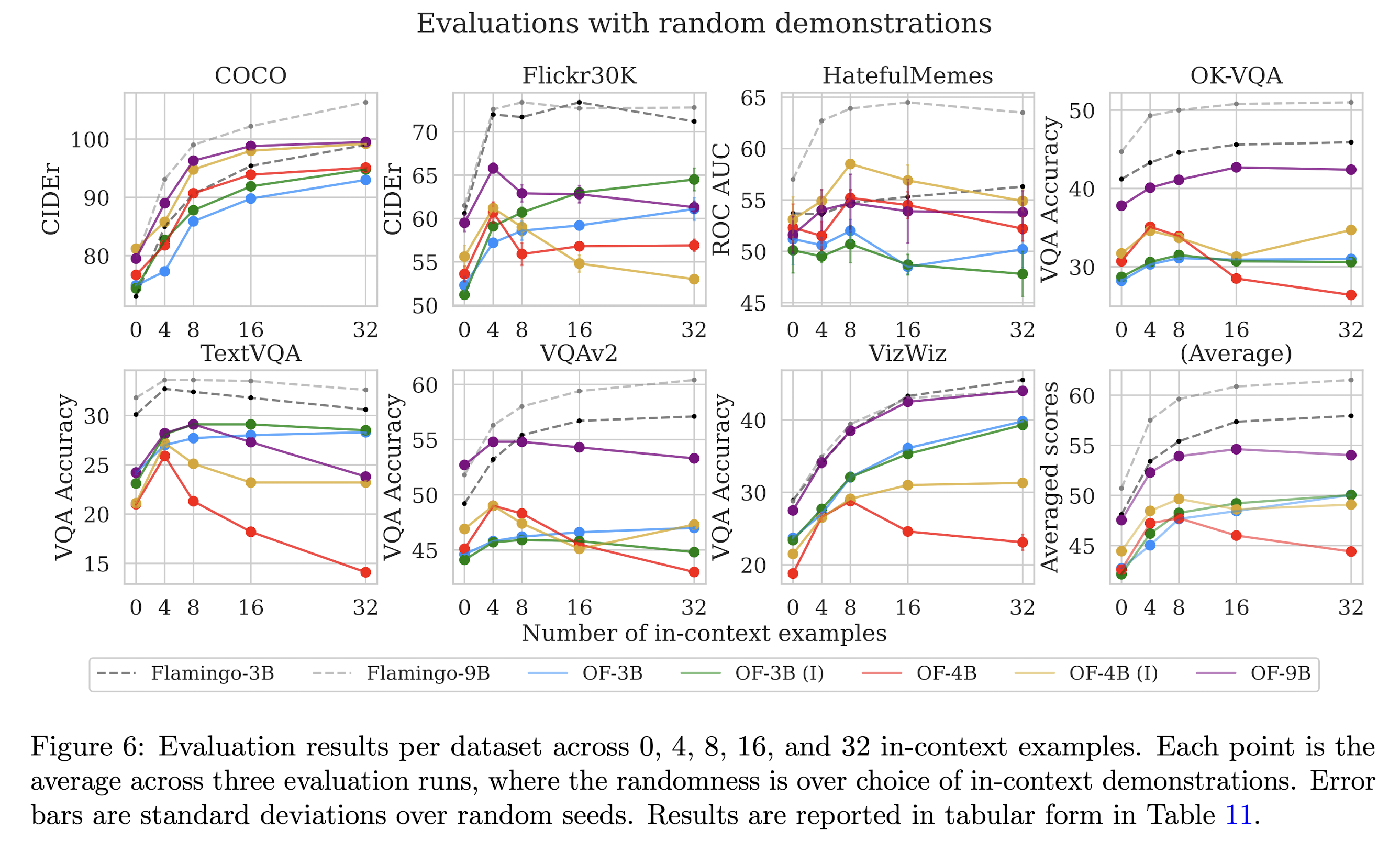
MM1, in contrast, does outperform Flamingo in a few-shot setting. They use two main techniques in the pre-training stage:
- Allow up to 16 images per sequence.
- Modify the self-attention masks to prevent tokens from attention across example boundaries when packing image-text pairs or interleaved documents along the sequence dimension.
Task Vectors for few-shot performance
Multimodal Task Vectors Enable Many-Shot Multimodal In-Context Learning describes how to improve VLM few-shot learning performance but now without custom fine-tuning. They do this based on the idea of Task Vectors: a recent finding (Function Vectors in Large Language Models, In-Context Learning Creates Task Vectors), showing that compact latent representations encode task-specific patterns inferred from examples in certain attention heads. Task vectors can be created by computing the mean activations of attention heads over a set of task examples and can be reduced by finding the attention head locations where the specific task is encoded. The model can then use the mean activations at inference time as a proxy for few-shot learning. This way, the model can use task-relevant information from many examples without:- using a large context for the examples
- specific fine-tuning
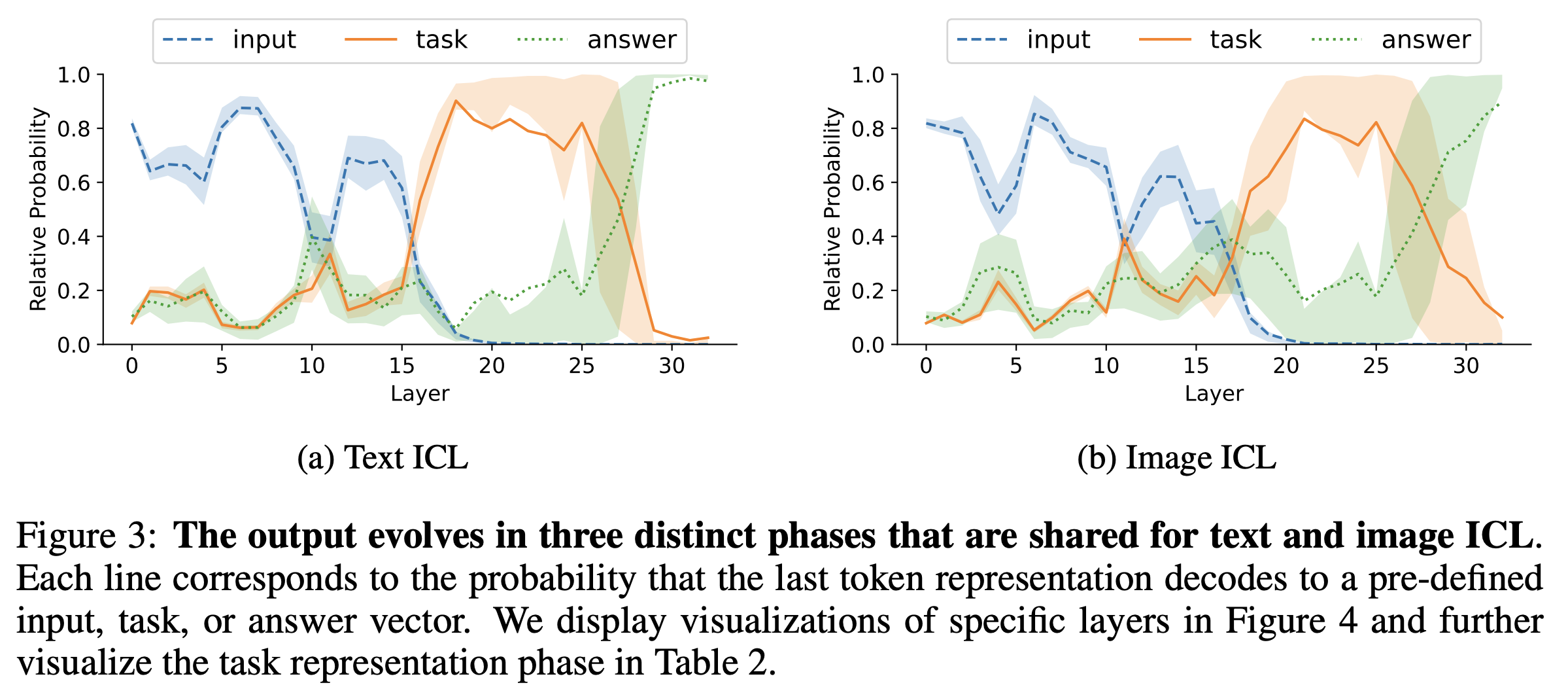
Conclusion
- Few-shot learning in SoTA VLMs leads to inconsistent results, most likely because of the pre-training task, which can include one or many images.
- Open-source VLM few-shot learning has several limitations: recency bias, reliance on text over images, and shortcut use, which makes few-shot learning not much better than KNN (depending on the task).
- Techniques such as task vectors and improved pre-training strategies (e.g., more images per sequence), can improve VLMs' few-shot performance.